

An Introduction to ZK-BulletProofs RollUps
#web3, #BulletProofs, #Cryptography, #Protocols, #Inner-Product-Proof, #Zero-Knowledge
Cryptography most commonly implies some kind of infeasibility assumptions. That is, in some way/direction or the other, it is not possible to break something. (note: statement is always contextual of the time period, ie. tools at hand). The question that naturally comes to your mind, should be: What is a discrete logarithm problem?
A discrete logarithm problem : one-way computation which makes it totally infeasible to compute an input given only the output. That’s a standard.
Zero-knowledge proof, or its core building zero-knowledge protocol A.K.A “privacy by design”, refers to a cryptographic protocols to prove that a certain statement is true, without revealing a secret, or what the statement is about. In a given scenario, one participant, known as the prover, can demonstrate the veracity of a specific statement to another participant, termed the verifier, without divulging any information beyond the factual truth of the statement. In transparency and privacy driven environment like distributed ledgers, the landscape of zero-knowledge protocols is destined to see a plethora of upcoming proposal. This article discusses a new kid on the block, adding to the widely known Zero-Knowledge Succinct Non-Interactive Argument of Knowledge (ZKSnark) and Zero-Knowledge Scalable Transparent Argument of Knowledge (ZKStark) (read about it here)
- namely >> the “Zero Knowledge BulletProofs”.
The concept first came about in a 2017 paper from Standford university in collaboration with the University College London where a team of researchers outlayed a proposal to dramatically improves proofing performance in blockchain processing, both in terms of proof artifacts size and verification time.
Let’s set the context first :
Popular belief, reminiscent from Blockchain early days (2009), wants it that crypto-networks would inherently protect interactive agents real-world identity (as in: the people participating in transactions). Fortunately or unfortunately, anonymous market places isn’t beloved neither by capitalism ( which MOTO is famous: know your customers) and/or law enforcement agencies (Tax authorities, Security Agencies, and so forth). Tremendous efforts have improved chain analysis techniques, and it may be fair to say that most of what has been “crypto” trading for the last decade is an open book with the right tools (metadata is a killer). That is, the blockchain does not offer absolute anonymity or confidentiality behind alphanumerical signers public keys (identifications of the wallets used by participants). And that’s a bummer for anyone concerned with marketplaces not subject to central oversight ( like a person living under complex state regime ), or minded with simple business endeavour where transparency over logistics or other business core matters may set the ground to loose a competitive advantage. Crypto-communities, in particular, are usually sensitive to privacy topics, and work to conceiving original blockchain promises, while broadening blockchain application uses.
So the question becomes, what can be, or should be, private on a blockchain? The primary usage of distributed ledger is to record transactions. How to ensure both transaction confidentiality AND ensure transaction validity? Here we should distinguish three things where discussing privacy and anonymity:
-
Transaction Value ( how much - actual amount being transacted )
-
Transaction Type ( what - ie. nature or category of the transaction (whether a funds transfer, a smart contract function call, a token exchange, etc.)
-
Transaction Graph ( whom is transacting with whom )
The following focus on transaction privacy vs validity for now, which regards what and in which amount (eg. confidentiality of the matter of the transaction) is being transacted, while leaving transactions graph, that is transaction anonymity, for a later post.
Note: The effectiveness of roll ups to preserve privacy may also depends on how they are implemented in a particular blockchain protocol. Some blockchains use these proofs in conjunction with other privacy-preserving techniques to enhance overall anonymity.
What are the common transactions denominator which makes a interaction being a transaction - and a transaction being a valid one ?
- The transaction signatures are correct (the participants provenance dwelling)
- Some transactional inputs, and some transaction ouputs
- The transaction inputs are unspent ( ie. participant hasn’t sold what they are selling, or money can’t be spent twice )
- A marginal fee for network processing, where Sum(inputs)=Sum(ouptuts)+Processing(Fee)
- Inputs: The total amount of cryptocurrency or tokens that the sender is transferring. This is usually coming from the sender’s wallet address.
- Outputs: The total amount that is being received by the recipient(s). This includes any change that might be returned to the sender if applicable.
- Processing Fee: Also known as the transaction fee, which is paid to the network facilitators (miners or validators) for processing the transaction.
- The Ability to verify the above for anyone/any transaction on the network, ie. transparency.
From a blockchain network consideration, the critical point of importance here for anyone using the network is to ensure that the transaction is valid, as the blockchain represents a source of truth. Any lack of trust in the network main chain veracity means dramatic usage reduction, forking, loss of capital, etc. However, the details of the transaction matters little, as long as the transaction is correct. And less details means more privacy. Hence would there be ways to conceil transactions details, while pertaining the ability to know that transactions are correct, or to put it in general term: allow privacy on the network without defaulting on it’s public verification prospects?
Some of the most promising attempts to privacy regarding amounts came with the concept of Confidential Transactions. These transactions “keep the amount and type of assets transferred visible only to participants in the transaction”, ie. obfuscate the amount transferred in transactions using Pedersen cryptographic commitments (discrete log based) from the general public**.** It’s like packaging the currency notes in an envelop**.** However, the very nature of such proposal (homomorphic commitment) imply deep structural protocol changes to public blockchains, notably the public transparency of transferred value part of the blockchain itself! In essence, a public observer wouldn’t be able to verify transactions anymore, as to statuate on the validity of the ledger. Putting this in place means that it becomes difficult to check that the above contraints over Sum(inputs)=Sum(ouptuts)+ProcessingFee is true. Essentially, is Sum(inputs) superior or equal to Sum(ouputs), the later being positive, plus the network processing fee, without the difference being sent back to the sender? In a negative case, this would mean that wealth was created out of thin air for the receiving wallet.
So we took another paradigm approach: posting only a proof of truth, that could be verified by anyone, where the prover ideally would not have to disclose any information about the value of the transaction amount. So came the use of Range Proofs. Range proof protocols by themselfs are ongoing vast research in a while area of applications, due to their potential usage in electronic voting, rating and investment grading, mortgage risk assessment. We shall bypass all technical details and specifics here, but essentially, when verifying the legitimacy of a transaction, the use of Range Proof protocol helps to verify that the amount transacted lies within a required range ( for example, that x amount is > 0)(hence the name)(read more here).
The idea could be resumed as follow, using Camenisch and Stadler notation for proofs of knowledge where greek letters are only known to prover:
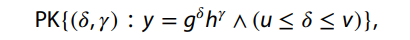
- PK stands for “Proof of Knowledge.”
- (δ,r) are the values for which the proof is being made.
- y is the value that is claimed to be the result of the operation
- g and h are the bases for the exponentiation, which are typically public parameters in the context of a cryptographic scheme
- δ and r are the exponents in the respective bases g and h and are the secret values that the proof is about.
- where u ≤ δ ≤ v. ie. u and v represent the lower and upper bounds, respectively, within which the value δ is claimed to lie.
These proofs, luckily, can be set as non interactive zero knowledge proofs (using Fiat-shiamir protocol ). We can attach these proofs to each block, so that everyone is convinced that the transaction is valid. However ( as in with some other non interactive proofs system like with ZKSnark ), adding the proof itself to each block impaires the efficiency of the verification and storage processes. These proofs size can be linear, that is, the more data comes in a transactions, the longer the proofs, the higher the storage costs. For example, a confidential transactions with just two outputs and 32 bits of precision would require roughly a zero knowledge range proof whose size is 5 KB, leading to transactions whose total size is equal to 5.4 KB, hence the proof itself contributing to 93% of the transaction size).
Here we approach the Bulletproofs proposal : effectively it’s a zero-knowledge argument of knowledge method that can prove that a secret lies within a given range (ie. a Range Proof), non interactive (versus. ZK-SNARK, where trusted setup requirement is usually little desirable), and is logarithmic in the size of the computation, which translates to staying relatively minimal as transactions input grows (similar to STARK). This and other protocol offers the promise significant storage efficiency, security, lower fees, and fast verification times. And it seems to deliver. The open-source privacy focused platform Monero implemented BulletProofs protocol early one, (since then have iterated applicative-driven improvements towards BulletProofs+ in their Ring Confidential Transactions), which resulted in a tremendous reduction of their transaction size and fees (+70%)
The BulletProof Protocol
Let’s dive in .
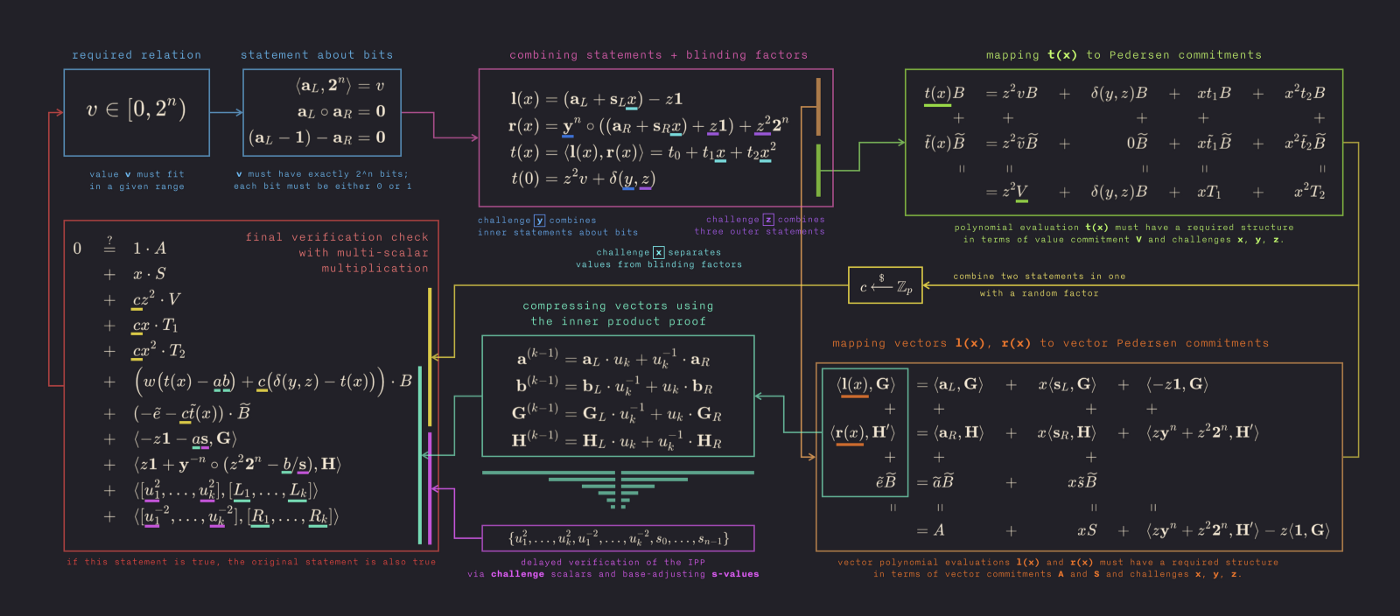
sources: Oleg Andreev’s stylized illustration of the Bulletproofs range-proof protocol cathieyun
or not. This is complexe algorihtmic circuit. We will attempt to summarize it for you by providing an english high-level overview, where the actual process involves advanced mathematical operations and cryptographic techniques.
Note: The actual implementation of a Bulletproofs protocol would involve the following steps in a more intertwined manner, with some steps being prerequisites for others. For example, the commitment scheme is a prerequisite for constructing zero-knowledge proofs, and the inner product proofs are a specific optimization used within the range proofs to make them more efficient. The aggregated range proofs and constraint system proofs are more advanced applications that build upon the basic zero-knowledge proof and commitment scheme.
High Level - pseudo-sequential approach - short
-
Commitment Scheme - Securely commit to a value while keeping it hidden.
-
Non-iterative Zero-Knowledge Range Proof -The process of proving that a committed value lies within a certain range.
2.1. Breaking Down the Value into Binary - Convert the transaction value into binary form for simpler range proof creation.
2.2. Forming Constraints Based on Binary Representation - Develop constraints that the binary digits must satisfy.
2.3. Converting Constraints into Polynomial Equations - Translate these constraints into polynomial equations for mathematical processing.
2.4. Cloak Protocol (Application of Constraint System Proofs) - Apply constraint system proofs to obfuscate transaction types. This step likely involves incorporating additional constraints related to the transaction type into the proof system.
2.5. Inner-Product Argument and Proof Construction - Construct a proof using an inner-product argument to demonstrate the validity of the polynomial equations.
2.6. Aggregated Range Proofs - Combine multiple range proofs into a single, more efficient proof.
High Level - pseudo sequential approach - explained.
It all starts with a commitment:
-
Commitment Scheme (Pedersen Commitment) Securely commit to a value while keeping it hidden.
- Overview: Imagine sealing something in an envelope; you know something is inside, but you can’t see what it is. Here, the idea is to building a proof on committed values, where the prover commits to (can’t retract or later alter ), and runs an arithmetic circuit, or computes a proof, on the commitment output (discrete logarithm), not the actual values.
- Process: The prover begins by committing to a value
vusing a Pedersen Commitment. This commitment, done through a function, produces an output Commitment(v), concealing the valuev. The commitment is designed to be hiding; it’s impossible to deducevfrom the commitment alone, thus ensuring privacy. Additionally, this commitment is homomorphic, meaning multiple commitments can be combined together. For instance, commitments to valuesaandbcan be added to form a new commitment that equals the sum ofaandb(i.e.,Com(a) + Com(b) = Com(a + b)). They are also irreversible: Once committed, the value cannot be altered, binding the committer to the original value and preventing dishonest behavior.
-
Non-Interactive Zero-Knowledge Range Proofs.
The process of proving that a committed value lies within a certain range.*- Overview: This step is like proving the envelope contains a non-negative amount of money without opening it. The prover creates a proof about the committed value
v, asserting its correctness without revealing any further information. Here, various steps are involved:
2.1 Breaking Down the Value into Binary
Convert the transaction value into binary form for simpler range proof creation.- Every numerical value can be represented in binary format, which is a base-2 numeral system using only two symbols: 0 and 1. The process of binary decomposition essentially means expressing the value
vin terms of these binary digits (v_bits). For example, ifvis 5, its binary representation would be 101.
- Overview: This step is like proving the envelope contains a non-negative amount of money without opening it. The prover creates a proof about the committed value
2.2 Forming Constraints Based on Binary Representation: Develop constraints that the binary digits must satisfy.
- Once
vis represented in binary, a series of mathematical “polynomial” constraints based on this representation are formulated. These constraints assert that each bit inv_bitsis either 0 or 1, and when combined (considering their respective powers of 2), they should sum up to the original valuev. These constraints are crucial for the range proof as they ensure the integrity of the binary decomposition.
2.3. Creating the Range Proof: Converting Constraints into Polynomial Equations:.
Translate these constraints into polynomial equations for mathematical processing.
Zero Knowledge range proof: a proof that a secret value is in a certain range, Example: 0 ≤ value < 2^n-1
- A range proof, which demonstrates that
vis within a specific numerical range, is constructed using these polynomial equations or R1CS representations. In simpler scenarios, the polynomial equations are direct translations of the binary constraints. However, for more complex proofs scenarios, an additional system called Rank-1 Constraint System (R1CS) can be used. It basically allows for the representation and handling of more intricate arithmetic and logical constraints. That is, each secret value that needs to be proven within a range can be translated into a corresponding set of constraints. For a range proof, these constraints ensure that the committed value, when represented in their binary format, results in a polynomial equation that only has solutions within the valid range. The idea is to generate a proof. This proof essentially demonstrates that the committed valuev, represented byv_bits, falls within a specific numerical range (hence the term “range proof”). Its construction verifies the correctness ofvwithin the desired range. If you are interested in the inner workings of range proof protocol, check out the further reading section below.
2.4. Cloak Protocol (Application of Constraint System Proofs).
Apply constraint system proofs to obfuscate transaction types. This step likely involves incorporating additional constraints related to the transaction type into the proof system. specifically address the issue of hiding the transaction type
- The Cloak Protocol is an application of constraint system proofs designed to maintain the confidentiality of both the asset types and the values involved in transactions. This includes ensuring that the types and amounts of assets are conserved through the transaction and that no asset is created or destroyed (outside of explicit issuance or burning), while the specific details about what is being transacted and how much are obscured from public view, at least to anyone not directly involved in the transaction., known as Confidential Assets Scheme. This constraint system is composed of various gadgets—modular components that enforce specific types of constraints. It can include “shuffle” gadgets (which prove that outputs are a permutation of inputs), “merge” and “split” gadgets (which handle the combining and dividing of asset types), and “range proof” gadgets (which prove that all amounts are within a valid range and not negative). Eventually, the Cloak Protocol is primarily dealing with polynomials that have been derived from the initial constraints to incorporate or manipulate these polynomials to achieve the desired level of privacy and confidentiality for the transaction type, along with the value.
However, at this point, the proof is still not complete. The prover then uses the arithmetic circuit to generate the final proof. This proof essentially shows that there exists an assignment to the variables in the circuit (which correspond to the bits of the committed value) that satisfies the circuit’s constraints. The proofing process uses the inner-product argument to validate these polynomial equations, ie. that they satisfy the correct form without revealing the individual bits of v_bits.
2.5. Inner-Product Argument and Proof Construction Construct a proof using an inner-product argument to demonstrate the validity of the polynomial equations.
-
Technique: This technique involves demonstrating that the polynomials derived from
v_bitssatisfy the correct form. The inner-product argument is a sophisticated cryptographic method to prove that two vectors have a certain inner product, which in the context of range proofs, verifies the correct binary decomposition and therefore the range. It confirms that the committed valuevis equal to the inner product<v_bits, 2^n>, where2^nis a vector of powers of 2. The inner product ofv_bitsand2^nreconstructs the original valuevifv_bitsis indeed the correct binary representation ofvthus confirming the binary decomposition and, consequently, the range ofv. This serves as an efficient method to prove that two vectors have a certain inner product without revealing the vectors themselves. This is done without revealing the actual values ofv_bits, thereby maintaining the zero-knowledge aspect of the proof. At this stage, it’s completely obfuscated. -
Verification Process: Originally, Bulletproofs were interactive, requiring a verifier to check the proof’s validity. However, the protocol evolved to adopt Non-Interactive Zero-Knowledge (NIZK) methods - Initial Argument: The prover starts with an argument based on
v_bits, creating vectors and other necessary cryptographic commitments. - Fiat-Shamir Heuristic: Instead of waiting for a verifier’s ramdom scalars challenge, the prover uses the Fiat-Shamir heuristic. Essentially, they would hash the current state of the proof (including all commitments) to generate a pseudo-random scalar, simulating the verifier’s challenge. - Recursive Halving: Using the generated scalar(s), the prover applies recursive halving, reducing the size of the vectors involved in the proof. The inner product proof in conjunction with halving techniques significantly reduces the computational and space complexity of verifying the correctness of an inner product between two vectors. Traditional methods would require linear time and space relative to the size of the vectors (O(n)), but inner product proofs can achieve this in logarithmic time and space (O(log(n))) thanks to recursively applying halving over the vectors involved in the inner product. Here, in each round of the protocol, the vectorsaandbare kind of split into two halves, and these halves and are recombined with the challenge scalar(s) generated. This reduces their size and, in turn, the proof size and verification time. The process is applied recursively until it produces a single aggregated value that can serve as a compact proof. The challenge scalars ensure that the prover cannot cheat by preparing the halves in a way that would only appear correct. They are essential for the security of the proof as they introduce randomness and are chosen after the prover commits to certain values, preventing any manipulation. - Final Proof: The prover completes the proof with any necessary final pieces of information to allow complete verification. The proof can be independently verified by any independant party using the same recursive verification process.
In the final output, the verifier receives the proofs (which may be individual or aggregated) and checks them against public parameters of the protocol, that is provided values and constraints. The verifier confirms that the proofs are valid, which means that the commitments translations are within the specified ranges, translating to the constraint system being satisfied, the transactions being correct, all without gaining any knowledge of the actual values or types involved in the transactions.
This is like someone verifying that a package only contains sealed envelopes which contains some things answering to some amount truths, which constraints system truthfullness can be verified without the need to open any of them, hence learning about the envelops amount.
2.6 Efficiency through aggregated Range Proofs.
Combine multiple range proofs into a single, more efficient proof.
- Bulletproofs protocols, and specifically bulletproofs roll ups typically involve multiple range proofs from different provers, where these are aggregated into a single, compact proof. Ie, instead of creating and verifying each proof separately, which would be linear in complexity with respect to the number of proofs, aggregation allows for a single proof that can be verified more quickly than the individual proofs separately. This is an advanced feature of the Bulletproofs protocol that enhance its efficiency and scalability. In this context, each prover uses their secret inputs to construct a satisfying assignment for their part of the constraint system (all steps as explained above). Even though the final proof is non-interactive, the construction of the proof itself can involve interactive protocols. A multi-party computation (MPC) or a dealer model may be used to facilitate the creation of this aggregated proof without revealing individual secrets. Multi-Party Computation: Allows multiple parties to create a single proof for multiple range statements.Here’s a simplified overview of how an MPC protocol might work:
- Sharing Phase: Each party uses secret sharing to distribute shares of their secret value among all parties. This ensures that no single party has access to another party’s secret, but collectively, the group can compute functions of the secrets.
- Computation Phase: The parties collaboratively perform computations on the shares. This can involve generating partial proofs or commitments that correspond to each party’s secret value. The crucial point here is that computations are done in such a way that no individual party gains enough information to deduce another party’s secret.
- Aggregation Phase: The parties combine their partial proofs or commitments into a single structure. In the case of range proofs, this would be a single proof that all the individual values are within the allowed range. The aggregation is done in a way that preserves the zero-knowledge property of the individual proofs.
- Fiat-Shamir Heuristic: Once the partial proofs are aggregated, the Fiat-Shamir heuristic is applied to make the protocol non-interactive. Instead of waiting for a challenge from a verifier, a hash function is used to generate the challenge deterministically based on the data that has been agreed upon so far.
- Final Proof Construction: The final non-interactive proof is constructed using the challenge(s) generated via the Fiat-Shamir heuristic. This proof can be verified by any external party without further interaction with the provers.
It’s like a group of people each putting their sealed envelope into a box and shaking it up; everyone knows there are envelopes inside, but nobody knows which envelope belongs to whom.
Dealer Model: In some implementations of aggregated range proofs, a trusted dealer may be used to coordinate the process. This dealer acts as an intermediary to facilitate the communication between the parties and assist in the construction of the aggregated proof. However, it’s important to note that the dealer does not learn any of the secret values during the process.
It’s as if checking one package is almost as fast as checking each envelope individually.
Zero Knowledge Protocol efficiency comparison.
The practicality of BulletProof protocols is both in its application, and in comparison to other solutions. The scaling behaviour ( eg. linear, logarithmic, constant, etc ) of an Arithmetic circuit can indicate how the size of its resulting cryptographic proof, that are typically expressed in bytes or bits unit, grows with the complexity of the computation, or the number of inputs/outputs. Logarithmic scaling is favourable in most scenarios as it leads to relatively small increases in proof size even as the computation becomes more complex. Smaller proof sizes are generally desirable as they require less data to be transmitted and stored back on the Layer-1, and usually can be processed, or verified, faster.
Well, let’s compare Proof Size vs Circuit Input, which should provide a solid understanding of protocols scaling behaviours:
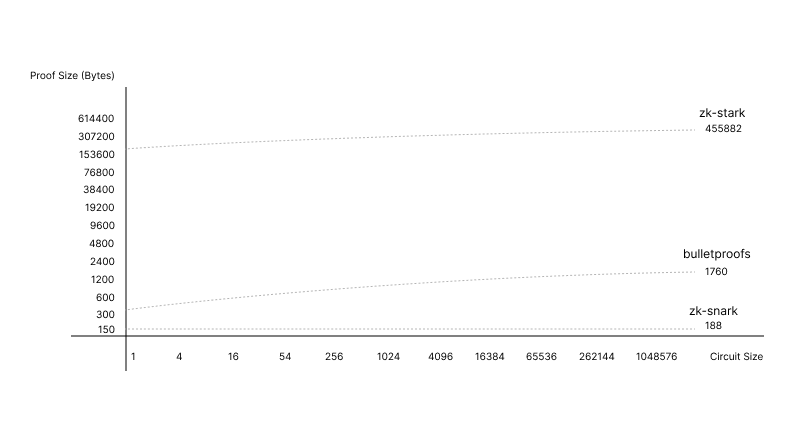
source: IEEE Symposium on Security and Privacy
The horizontal axis in the graph is labeled with numbers that represent a circuit size. “Circuit size” typically refers to the complexity of the computation that the zero-knowledge proof is proving. It’s a measure of how many basic operations, such as additions and multiplications, are needed to describe the computation. Usually, circuit size can be measured in terms of Gates (eg. The number of logic gates in a circuit in the case of boolean circuits) and Constraints (eg. The number of constraints that need to be satisfied for the computation in the case of arithmetic circuits). As the numbers increase, they indicate larger and more complex circuits, which generally require more computational effort to generate a zero-knowledge proof.
- ZK-STARTK : 250 000 Bits - the proof size starts higher than SNARKs and Bulletproofs for small circuits but scales logarithmically, suggesting great scalability for larger circuits.
- ( Confidential transactions range proofs : 4000 (linear) Bits )
- ZK-Bulletproofs : 370 Bits - Lower proofs sizes than ZK-STARK (less storage hungry on mainnet). which proofs size scale logarithmically, making them more efficient as the number of elements to be proved increases.
- ZK-SNARKS : 188 Bits - The curve is relatively flat or constant, indicating that the proof size does not increase much even as the circuit complexity grows. This property makes SNARKs highly efficient for scalability in terms of proof size, but they require a trusted setup, which is a consideration for their use.
What is important here, it the logarithmic scaling of the bulletproof curve, prior to previous linear one. That is, the larger the statement you are trying to proof (like a Layer-2 batching thousands of transactions), the larger the savings versus other traditional proofs systems. Coupled with a relatively small proof size (compared to ZK-STARK), but remaining non-interactive (against the common pitfall of ZK-SNARK), we may well have an economic incentives to batch process on Layer-2 with BulletProofs protocols.
===
That’s it for now!
We hope that this has clarified the topic to some extent and revealed that these protocol scenarios are not overly intricate. If you wish to delve deeper into the finer details of the Bulletproof protocol, please refer to the links provided below. Alternatively, you can explore additional articles on blockchain scaling solutions on our blog. Thank you for reading